Introduction
This document shows some basic web scraping steps to crawl Vietnamworks and get 50 newest jobs.
Below are some libraries used in this doc:
- BeautifulSoup 4: worker for all scraping activities
- requests: very powerful library, but main usage in this doc will be send GET requests to some websites
- pandas: very popular data wrangling library
- matplotlib: a popular Python library for plotting 2D data
- seaborn: a Python library for statiscal visualization
Note: I wrote these code in IPython Notebook, so some commands might not work for you if you are working in some text editors, especially for displaying graphs and tables. For the best, please use IPython Notebook to work with this tutorial.
Installing requirements
Install necessary libraries:
pip install beautifulsoup4
pip install requests
pip install pandas
pip install seaborn
pip install matplotlib
Import:
import requests
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from bs4 import BeautifulSoup
%pylab inline
Go to Vietnamworks.com, choose any job category, this document will choose IT-Software and configure so that Vietnamworks display 50 jobs per page.
Crawling and Scraping
Store the Vietnamworks URL to crawl in variable url:
url = 'http://www.vietnamworks.com/it-software-jobs-i35-en'
Store the page’s DOM in BeautifulSoup:
soup = BeautifulSoup(req.content, 'html.parser')
To see what soup looks like:
soup
Now what we need to do is to find the DOM element that contains all the job posts in this page. After inspecting the code using Developer Tools, we know that these 50 job posts are stored in a table element with classes table table-hover link-list table-expanded.
Let’s get that element out of the page’s DOM using BeautifulSoup, by looking for table element with class link-list. One class maybe enough to get the desired table from this website, but it will be different for different websites:
jobs_table = soup.find('table', {'class': 'link-list'})
Let’s take a look at this:
jobs_table
Through the look of it at first, I think we already got what we are looking for. Now, get all job posts in this table, using BeautifulSoup find_all() method.
The result will be a list of all job posts, each job will be stored in a tr element, a table row:
tr_tags = jobs_table.find_all('tr', {'class': 'job-post'})
How many job posts are there?
len(tr_tags)
The output will show exactly 50, just as we expected. So we are going in the right direction!
Now, it’s time to scrape detail information for each job. We will extract the following:
- Job title
- Company
- Location
- Link
Because there are 50 jobs, so we will store each piece of information in a separate list. So totally 4 lists are created, one for Job title, one for Company and so on. This is handy because we can use these lists to formulate a Pandas Frame later, which is a very powerful for data management if we want to explore the data further.
First, get the Job title:
job_titles = [title.find('a', {'class': 'job-title'}).contents[0] for title in tr_tags]
# Now take a look at first 3 titles
job_titles[:5]
Output:
[u'K\u1ef9 S\u01b0 C\xf4ng Ngh\u1ec7 Th\xf4ng Tin ( V\u0103n Ph\xf2ng Qu\u1ed1c Gia L\xe0ng Tr\u1ebb EM SOS Vi\u1ec7t Nam )',
u'Nh\xe2n Vi\xean X\u1eed L\xfd B\u1ea3n V\u1ebd CAD Bi\u1ebft Ti\u1ebfng Nh\u1eadt',
u'Nh\xe2n Vi\xean CNTT ( Qu\u1ea3n Tr\u1ecb Ph\u1ea7n M\u1ec1m, Qu\u1ea3n Tr\u1ecb H\u1ea1 T\u1ea7ng )',
u'Senior Java Web Developer ($1,000 ~ $1,200)',
u'Project Manager \u2013 Microsoft Technology']
It seems good. So what happened?
For each tr tag in the jobs_table, we find the a tag with class job-title. This will return the DOM for the job’s title along with its hyperlink. Because we know that there will be only one a tag with class job-title, the find() method works fine. Then contents variable is used to get the text between open and close a tag. This variable will return a list with 1 element, so [0] will get the first element out, which is the title itself.
Next we will get the remaining information for each job post and store them in corresponding list. The logic is the same. All we need to do is to inspect the DOM that contains necessary information and use BeautifulSoup to extract it.
# Get hyperlink to job's detail page
job_links = [job.find('a', 'job-title').get('href') for job in tr_tags]
# Employer
job_companies = [job.find('span', 'name').contents[0] for job in tr_tags]
# Job's location
job_locations = [job.find('p', 'job-info').contents[1].find('span').contents[0] for job in tr_tags]
After getting all required pieces of data, we may proceed to combine them into a data structure that is more useful for further analysis. Pandas DataFrame is the best candidate for this job. To read more about Pandas, please refer to the link at the beginning of this document.
data = pd.DataFrame({'title': job_titles,
'company': job_companies,
'job_location': job_locations,
'link': job_links})
data.head(5)
Output:
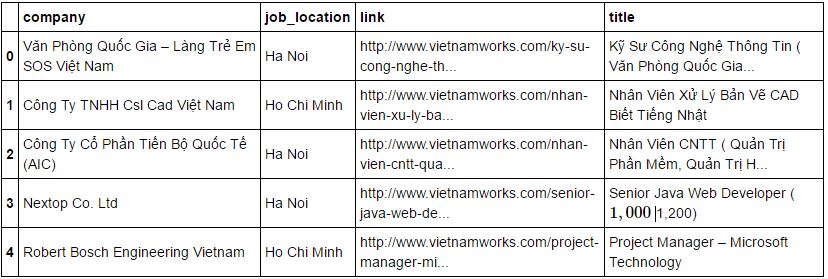
Exploring Data
DataFrame helps us to view, transform and visualize data very effectively. For example, you can get the overview of how many jobs out of 50 extracted jobs above are based in Hanoi, Ho Chi Minh, …
To do this, we can use matplotlib and seaborn with a painless function as below:
sns.countplot(y=job_locations, data=data)
Output:
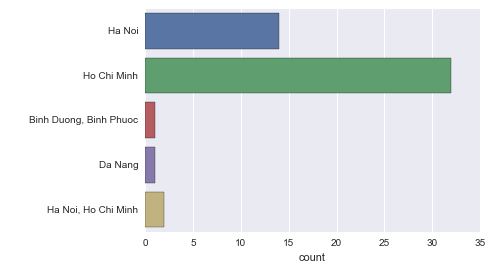
So clearly, the vast majority number of jobs are based in Ho Chi Minh city.
Visit matplotlib and seaborn websites for more.
« Homepage